
Desarrollo y aplicación de técnicas de extracción de información en Data Science
Objetivos y finalidad
El grupo Desarrollo y aplicación de técnicas de extracción de información en Data Science trabaja sobre una serie de temas:
1. Modelado de datos no convencionales
En el modelado de datos el Diagrama de Entidades y Relaciones Extendido es una pieza clave, a partir del cual mediante procesos de transformaciones se genera un esquema físico de datos, en su gran mayoría, basado en un modelo Objeto-Relacional. En dicho proceso existen una variedad de problemas, originados por la falta de herramientas y metodologías que permitan expresar la semántica de determinadas situaciones.
Para el caso de datos morfométricos se plantean nuevas perspectivas y necesidades de procesamiento de datos, que difieren de aquéllas ya firmemente establecidas en los sistemas que procesan datos convencionales, más específicamente la morfometría geométrica utiliza coordenadas cartesianas en 2D o 3D de puntos anatómicos específicos que pueden ser claramente identificados y registrados en todos los organismos cuya forma se quiere analizar y/o comparar. Lo anterior hace necesario estudiar la semántica de este tipo de datos para poder encontrar las mejores formas de representación dentro de un modelo conceptual.
2. Técnicas Cuantitativas Orientadas al Reuso Semántico de Modelos de Requisitos

Los modelos LEL, Escenarios Actuales , Escenarios Futuros y Especificación de Requisitos (SRS) son construidos para dar soporte al proceso de definición de los requisitos del software. Sin embargo, su mera observación objetiva muestra que contienen más información que la que explícitamente se indica. Por ejemplo, la existencia de dos símbolos del LEL que son claramente sinónimos parciales, muestra que existe una jerarquía cuyos miembros no pertenecen al LEL en su totalidad. Esto indica que el Universo de Discurso ha fallado en plasmar en su vocabulario todas las abstracciones posibles que emergen de su problemática, o que la captura del glosario ha sido incompleta. Para poder extraer ésta y muchas otras informaciones de los modelos del proceso de Ingeniería de Requisitos, se requiere construir grafos, contar referencias, calificar relaciones y otros mecanismos que aún se desconocen. Este es el eje de las actividades de esta línea de investigación, ya que se pretende sistematizar el metaconocimiento disponible y enfatizar el uso de diferentes técnicas basadas en estrategias cuantitativas.
3. Clusterización en imágenes multiespectrales

Obtener información de imágenes satelitales requiere ordenar y agrupar una gran cantidad de datos multidimensionales. Las técnicas de Clustering implementadas en computadoras hasta la fecha, brindan soluciones aceptables; sin embargo, tienden a ser lentos y pueden requerir intervención humana en muchos pasos del proceso. Además, algunas de estas técnicas dependen en gran medida de las inicializaciones específicas y contienen pasos no deterministas, lo que lleva a un largo proceso de prueba y error hasta que se encuentre un resultado adecuado. El grupo ha desarrollado a FAUM: Fast Autonomous Unsupervised Multidimensional, un algoritmo de Clustering automático que puede descubrir agrupaciones naturales en big data. Se basa en generar diferentes histogramas multidimensionales, definidos como Hyper-histogramas, y elegir uno para obtener la información. Faum tiene como objetivo optimizar los recursos proporcionados por una computadora moderna. Cuando se inició la presente investigación, la idea era desarrollar un método de inicialización determinista de K-Means, sin proporcionar el número de clústeres para encontrar y aplicable a las Imágenes Satelitales. Durante la fase de prueba, se encontró que el algoritmo también se puede extender a un algoritmo de Clustering cerrado en sí mismo. Además, se puede generalizar fácilmente para procesar cualquier gran conjunto de datos multidimensionales, con un rendimiento notable en comparación con K-Means. Aunque el algoritmo es autónomo, puede ajustarse manualmente, si se desea. Faum trata el proceso de Clustering como una sucesión de pasos. Cada paso extrae información relevante del conjunto de datos de entrada, generando un conjunto de datos nuevo y más pequeño, que se utilizará en el siguiente paso. A la fecha se ha publicado los primeros dos pasos de Clustering de Faum, que obtiene resultados aceptables con conjuntos de datos que contienen grupos simétricos esféricos disjuntos, similares a los K-Means. En este punto, Faum se puede considerar un método de agrupamiento lineal. Se están investigando más pasos y se presentarán en el futuro. Estos pasos podrían permitir a Faum abordar clusters no lineales, o incluso incluir otras técnicas no lineales actualmente en uso, como COLL, MEAP, entre otras, que podrían aprovechar la reducción del tamaño del conjunto de datos.
4. Sistemas de asistencia al diagnóstico y al tratamiento


La determinación de la dosis de radiación absorbida en tejido humano es de suma importancia para lograr un tratamiento de radioterapia eficaz. El método más preciso para estimar la dosis es el cálculo basado en Montecarlo pero los programas que realizan este cálculo han debido optar por alguna de las variantes en el compromiso, aún no resuelto apropiadamente, entre la calidad de la estimación y el costo temporal del cálculo. Muchas de las técnicas existentes de reducción de tiempo se basan en una simplificación del problema y acarrean una pérdida de calidad en los resultados. Se han aplicado técnicas de cálculo directo, el precálculo y la paralelización que permiten reducir el tiempo de cálculo sin perder calidad en los resultados realizando un cálculo completo sin simplificaciones.
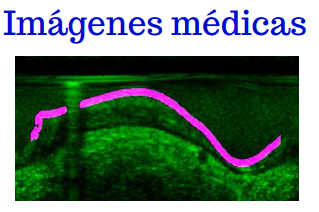
La digitalización de las diferentes modalidades de imágenes médicas y su disponibilidad facilita el desarrollo de herramientas de procesamiento digital de imágenes con el fin de brindar soluciones de asistencia al diagnóstico. En este sentido se han aplicado redes neuronales convolucionales (CNN) en una variedad de problemas de segmentación y clasificación en imágenes médicas. Estas imágenes presentan varios desafíos para la implementación de Deep Learning, tales como la existencia de diferentes modalidades, la dificultad en el etiquetado por expertos (Ground Truth) y los defectos propios de las imágenes médicas. Se ha trabajado en la implementación de técnicas basadas en Deep Learning principalmente en problemas de segmentación de la pared vascular en imágenes de ultrasonido intravascular, en caracterización de hueso trabecular, en conteo de células en imágenes hiperespectrales de microscopía de fluorescencia y otros problemas. Además, se está trabajando en el reconocimiento de patrones de uso en herramientas de rehabilitación cognitiva. Para esto se están desarrollando un conjunto de herramientas y se aplican técnicas de procesamiento de imágenes para la detección de patrones, por ejemplo de detección de la mirada.